
Yhä useampi on testaillut työssään AI-agentteja: ne lupaavat lukea koko koodipohjan, ymmärtää kaiken ja automatisoida kehittäjän työn. Dokumentaatiota ja esimerkkejä on valtavasti, mutta kokonaiskuvan hahmottaminen AI-agenttien toiminnasta on yllättävän vaikeaa.
Halusin tämän käytännön esimerkin kautta oppia toteuttamaan yhden selkeän AI-agentin, perustuen aitoon käyttötarpeeseen. Tavoitteena ei ollut rakentaa kaikkea osaavaa superagenttia, vaan ymmärrettävä, rajattu ja edullinen kokonaisuus, joka tekee kontrolloidusti ja hyvin yhden asian.
Tässä blogissa käyn läpi:
- Mikä AI-agentti oikeasti on?
- Erot AI-avusteiseen koodiin tai ohjelmaskriptiin
- Miten AI-agentti rakennetaan käytännössä?
- Mitä tämän harjoitukseni agentti tekee ja mitä se ei tee?
- Miten kustannukset ja riskit pidetään hallinnassa?
Lopussa on lyhyt terminologialistaus, joka helpottaa lukemista. Osa termeistä on tarkoituksella epämuodollisia, mutta niiden merkitys on listauksessa pyritty täsmentämään.
Käyttötapaus: nopea ymmärrys uudesta koodirepositoriosta
Haluan ymmärtää nopeasti, mitä jokin GitHub-repositorio tekee ja miten se on rakennettu ilman, että luen koko koodipohjaa. Voin antaa parametrina joko GitHub-URL:n tai lokaalin hakemistopolun. Haluan myös nähdä, mitä agentin ajaminen maksaa.
Tavoite vastaa esimerkiksi kehittäjän ensimmäistä hetkeä uuden projektin äärellä. Tai suurten repomäärien analysointia ja koosteen luontia.
“Mikä tämä on, miten se toimii ja mistä kannattaa aloittaa?”
Tämä tarkoittaa käytännössä 5–10 minuutin ihmistyötä vastaavaa kokonaiskuvaa, ei tuntien koodinlukua.
Miksi valitsin tähän käyttötapaukseen “laiskan” agentin?
Netissä törmää usein agentteihin, jotka lupaavat:
- lukea koko koodipohjan
- ymmärtää jokaisen funktion
- refaktoroida projektin automaattisesti
Käytännössä tämä saattaa johtaa:
- suuriin työkalun token-kustannuksiin
- vaikeasti ennustettavaan toimintaan
- keskinkertaisiin lopputuloksiin
Tässä projektissa agentti on tarkoituksella rajattu toteuttamaan vain yhden selkeän toiminnan:
- se ei lue kaikkea, vaan laajuus on parametrisoitavissa.
- se ei analysoi jokaista tiedostoa, mutta tarkkuus on parametrisoitavissa.
- se keskittyy perehdytysvaiheen eli onboarding-tason ymmärrykseen.
Onboarding-tason ymmärryksellä tarkoitetaan samaa tietotasoa, jonka kehittäjä tyypillisesti haluaa saavuttaa avatessaan uuden koodirepositorion ensimmäistä kertaa. Agentin tavoitteena ei ole ymmärtää kaikkia yksityiskohtia, vaan vastata nopeasti seuraaviin kysymyksiin:
- Mitä tämä projekti tekee?
- Mikä on sen pääasiallinen käyttötarkoitus?
- Millä teknologioilla se on toteutettu?
- Miten projekti todennäköisesti ajetaan tai otetaan käyttöön?
- Mistä koodista tai tiedostoista kannattaa aloittaa, jos haluaa ymmärtää lisää?
Tämä vastaa ihmisen omaa onboarding-prosessia: ensin hahmotetaan kokonaiskuva ja vasta sen jälkeen siirrytään yksityiskohtiin. Agentti toimii tässä ikään kuin ensimmäisenä oppaana projektiin.
Rajaukset eivät ole heikkous, vaan koko agentin toimivuuden edellytys. Ilman selkeää käsitystä siitä, mitä “riittävä ymmärrys” tarkoittaa, agentti joko lukisi liikaa, jolloin kustannukset kasvavat tai se yrittäisi päätellä asioita, joihin sillä ei ole riittävästi kontekstia.
Mitä AI-agentti oikeasti on?
AI-agentti ei ole pelkkä yksittäinen LLM-kutsu tai chatbot.
Nyrkkisääntö:
AI-agentti = LLM (Large Language Model eli kielimalli) + päätöksenteko + rajattu ympäristö
Agentin toiminta perustuu klassiseen silmukkaan:
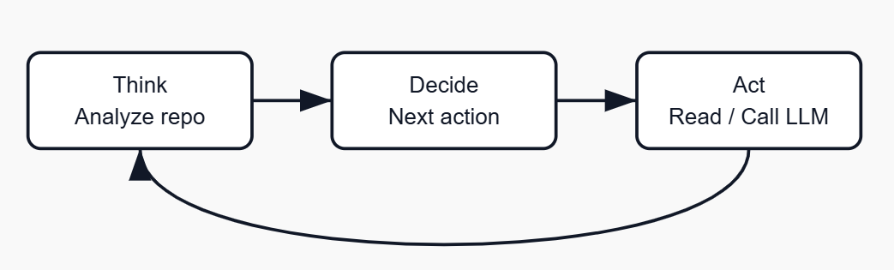
- Think: havainnoi ja analysoi
- Decide: päättää seuraavan askeleen
- Act: toteuttaa päätöksen
Tämä malli tekee agentista:
- modulaarisen
- laajennettavan
- helpommin testattavan
- turvallisemman virhetilanteissa
Agentti: tässä käyttötapauksessa toteutettava reposkanneri
Havainnoi ympäristöä (repo, tiedostot, metadata)
Agentti listaa repositorion hakemistorakenteen rajatulla syvyydellä ja lukee metatietoa, kuten tiedostojen nimet, sijainnit ja koot. Se havaitsee esimerkiksi, että repositoriossa on README.md, pyproject.toml ja FastAPI-hakemisto, mikä viittaa Python-kirjastoon tai FastAPI-projektiin.
Tekee päätöksiä epävarman tiedon pohjalta
Kaikki tieto ei ole yksiselitteistä. Agentti päättää, mitkä tiedostot ovat todennäköisesti tärkeimpiä ja jotka luetaan ensin. Jos README.md löytyy, se priorisoidaan. Jos README puuttuu, agentti voi päättää lukea pyproject.toml- tai setup.py-tiedoston ymmärtääkseen projektin luonteen.
Suorittaa toimintoja
Päätöksen perusteella agentti lukee valitut tiedostot, kutsuu kielimallia generoidakseen README-yhteenvedon tai tulostaa käyttäjälle raportin projektityypistä ja keskeisistä havainnoista. Tämä vastaa konkreettisia toimintoja, kuten tiedoston avaamista, tekstin rajaamista ja LLM-kutsun tekemistä.
Arvioi tilannetta uudelleen
Jokaisen toiminnon jälkeen agentti päivittää tilannekuvaansa. Jos luettu tiedosto ei ollut hyödyllinen, vaan se sisälsi esimerkiksi liikaa tai epäolennaista sisältöä, agentti merkitsee sen käsitellyksi ja päättää seuraavan askeleen uudelleen. Samalla se tarkistaa token-budjetin ja voi päättää pysähtyä, jos budjetti on lähellä ylärajaa: Think → Decide → Act.
Toteutettavan agentin toiminta ja rajaukset
Toteutettava agentti on rajattu ja tarkoituksenmukainen reposkanneri, jonka tehtävänä on auttaa ymmärtämään repositoriorakenne nopeasti ja kustannustehokkaasti. Agentin tulee toimia sekä lokaalissa ympäristössä että etärepositorioiden kanssa. Se noudattaa koko ajan ennalta määriteltyjä käyttö- ja kustannusrajoja.
Toiminnot
Agentti pystyy lukemaan koodia joko käyttäjän antamasta URL-osoitteesta, esimerkiksi GitHub-repositoriosta tai paikallisesta hakemistosta. Se listaa repositorion rakenteen rajatulla syvyydellä, jotta kokonaiskuva syntyy ilman, että kaikki tiedostot käydään läpi.
Agentin toiminnan kriittiset osat ovat konfiguroitavissa. Käyttäjä voi määrittää muun muassa:
- maksimimäärän tokeneita per LLM-kutsu ja koko ajokerralle
- kuinka syvälle hakemistorakenteeseen agentti saa mennä
- kuinka suuria tiedostoja voidaan lukea
Agentti sisältää virheenkäsittelyä ja fallback-logiikkaa, joiden avulla se pystyy reagoimaan vikatilanteisiin, kuten puuttuviin tiedostoihin, virheellisiin URL-osoitteisiin tai liian suuriin tiedostoihin ilman, että koko ajokerta epäonnistuu.
Analyysin aikana agentti tunnistaa projektityypin hyödyntämällä tiedostorakennetta ja metatietoja. Esimerkiksi FastAPI, Flask tai Django-viitteet auttavat luokittelemaan projektin oikein. Tämän perusteella agentti valitsee vain muutaman keskeisen tiedoston luettavaksi, kuten README.md, konfiguraatiotiedostot ja projektin entry pointin.
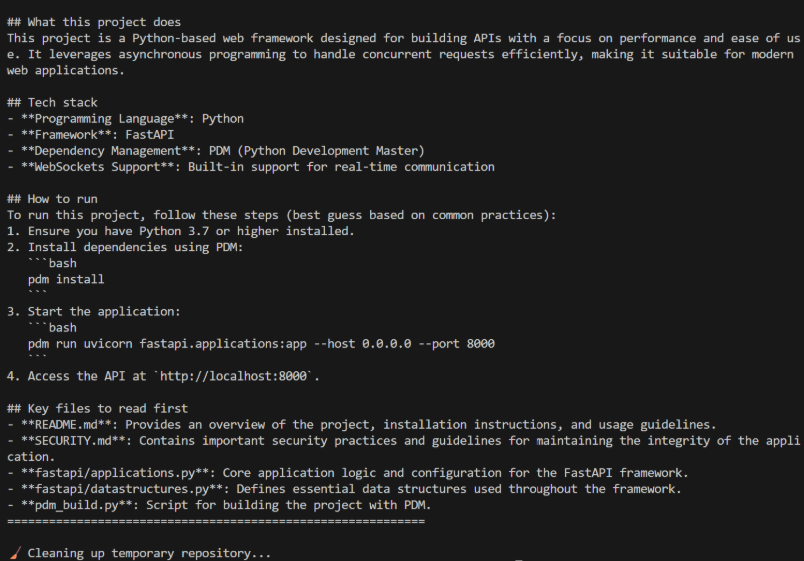
Näiden tietojen pohjalta agentti generoi README-tyylisen yhteenvedon, joka kattaa:
- projektin todennäköisen tarkoituksen
- käytetyn teknologiapinon
- karkean rakenteen
- arvion siitä, miten projekti ajetaan tai otetaan käyttöön
- ehdotuksen siitä, mistä koodista perehtyminen kannattaa aloittaa
Rajaukset
Agentti ei lue koko koodipohjaa, vaan se toimii rajatun lukusyvyyden ja tiedostomäärän puitteissa. Tämä on tietoinen päätös, jolla pidetään kustannukset, suorituskyky ja toiminnan ennustettavuus hallinnassa.
Agentti ei suorita koodia, eikä se tee muutoksia repositorioon. Repositorio voidaan tarvittaessa kloonata tai lukea vain analyysitarkoituksessa, mutta agentilla ei ole kirjoitusoikeuksia. Tämä parantaa turvallisuutta ja tekee agentin käytöstä riskittömämpää.
Lisäksi agentti ei takaa täydellistä analyysiä. Sen tuottama tieto on parhaimmillaan onboarding-tason ymmärrystä, eikä syvällistä arkkitehtuuri- tai laatuanalyysiä. Tämä rajaus on olennainen osa agentin toimivuutta ja käyttötarkoitusta.
Teknologiapinot ja valinnat
Tässä projektissa kaikki valinnat tehtiin tukemaan nopeaa oppimista, matalaa kustannusta ja helppoa muokattavuutta. Tarkoituksena ei ollut käyttää uusimpia tai monimutkaisimpia työkaluja, vaan rakentaa toimiva kokonaisuus mahdollisimman suoraviivaisesti.
Ohjelmointikieli: Python
- laaja ekosysteemi
- erinomainen LLM-tuki
Kielimalli: GPT-4o-Mini
- hyvä laatu onboarding-tasolle
- nopeat vasteajat
- matalat kustannukset
LLM-palvelu: Azure OpenAI
- selkeä avainten ja käyttöoikeuksien hallinta
- kustannus- ja käyttörajat
- olemassa oleva subscription, johon resurssit voitiin luoda nopeasti
Agentin logiikka on erotettu LLM-kutsusta, jotta palveluntarjoajaa voi vaihtaa helposti käyttäen esim. OpenAI:n suoraa API:a tai muiden pilvitarjoajien LLM-rajapintoja.
Käytännön toteutus
Varsinainen ohjelmakoodi toteutettiin Pythonilla yhteistyössä ChatGPT:n kanssa. ChatGPT toimi projektissa parikoodaajana: se auttoi arkkitehtuurin hahmottamisessa, agentin Think → Decide → Act -loopin rakentamisessa sekä virhetilanteiden ja reunatapausten huomioimisessa. Tavoitteena ei ollut automatisoida koodausta, vaan käyttää kielimallia tukena suunnittelussa ja iteroinnissa.
Toteutusta kehitettiin pala kerrallaan, jokainen toiminnallisuus lisäten ja testaten erikseen. Näin lopputuloksena syntyi toimiva ja hallittu kokonaisuus, joka vastaa määriteltyä käyttötapausta. On hyvä huomioida, että testaus ei ollut kattavaa, eikä toteutus ole sellaisenaan tuotantokelpoinen. Se on kuitenkin tarkoituksella rakennettu oppimista ja kokeilua varten, eikä valmiiksi tuotteeksi.
Koko koodi on saatavilla GitHubissa:
https://github.com/toced/repo-scanner
Luodun koodin rakenne lyhyesti
Koodi on jaettu pieniin, selkeästi vastuutettuihin moduuleihin. Tavoitteena on, että agentin toimintalogiikka, päätöksenteko ja ulkoiset integraatiot pysyvät erillään toisistaan ja kokonaisuus on helppo ymmärtää ja laajentaa.
Tiedostorakenne heijastaa agentin elinkaarta, eikä pelkkää teknistä kerrostusta.
agent.py
Vastaa komentorivikäyttöliittymästä ja käyttäjän syötteestä. Käyttäjä antaa joko paikallisen hakemistopolun tai URL-osoitteen, jonka perusteella agentin suoritus käynnistetään.
core.py
Sisältää agentin pääsilmukan ja toteuttaa Think → Decide → Act -mallin. Koordinoi agentin tilaa, kutsuu päätöksentekoa ja käynnistää varsinaiset toiminnot.
detector.py
Tunnistaa projektityypin repositorion rakenteen ja tiedostojen perusteella (esim. FastAPI, Flask, Django). Tämä tieto ohjaa agentin myöhempiä päätöksiä.
decide.py
Sisältää agentin päätöksentekologiikan. Valitsee seuraavan toiminnon agentin nykytilan, havaintojen ja käytettävissä olevan budjetin perusteella.
repo_loader.py
Vastaa repositorion sisällön lukemisesta joko URL:sta tai lokaalista hakemistosta. Huolehtii tiedostojen listauksesta, lukusyvyyden rajoittamisesta ja tiedostokoon tarkistuksista.
state.py
Määrittelee agentin tilan. Säilyttää tiedon jo luetuista tiedostoista, käytetystä token-määrästä, jäljellä olevasta budjetista ja muista päätöksenteon kannalta olennaisista tiedoista.
summarizer.py
Generoi README-tyylisen yhteenvedon agentin keräämien tietojen perusteella. Kutsuu kielimallia ja muotoilee vastauksen käyttäjälle luettavaan muotoon.
llm.py
Kapseloi Azure OpenAI -integraation. Vastaa LLM-kutsuista, token usage -seurannasta ja kustannusarvioiden laskemisesta. Tämä erottelu mahdollistaa palveluntarjoajan vaihtamisen ilman muutoksia agentin muuhun logiikkaan.
tools.py
Sisältää agentin käyttämät apufunktiot ja “työkalut”, kuten tiedoston lukemisen, tekstin rajaamisen, URL-tarkistukset ja muut pienet, mutta toistuvat operaatiot.
.env
Sisältää konfiguroitavat asetukset, kuten token-rajat, kustannusrajat ja API-avaimet. Mahdollistaa turvallisen ja hallitun kokeilun ilman kovakoodattuja arvoja.
Ohjelman ajaminen ja tuotettu raportti
Ohjelmaa testattiin useammalla repolla. Alla yksi esimerkki ”https://github.com/tiangolo/fastapi” repon skannauksesta.
Käynnistys: ”python3 ./agent.py”

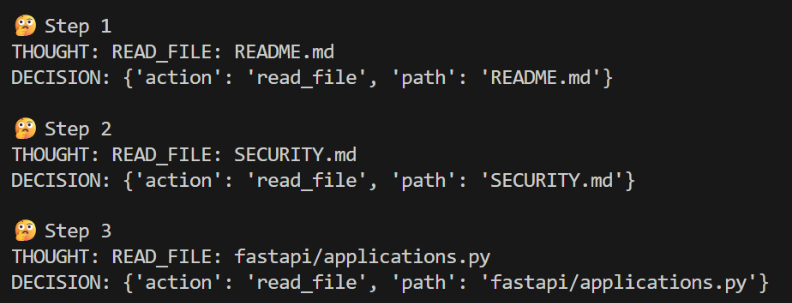
Ohjelma käy läpi tiedostoja:
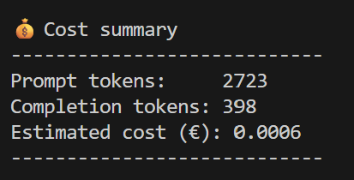
Tuottaa kustannusraportin:
Tulostaa varsinaisen koosteraportin:
Huomioita toteutuksesta ja agentin suorituksesta
Nykyisessä muodossaan agentti toimii parhaiten Python-repositorioiden kanssa. Tämä johtuu siitä, että projektityypin tunnistus, tiedostojen valintalogiikka ja oletukset rakenteesta on rakennettu Python-ekosysteemi mielessä pitäen. Esimerkkeinä pyproject.toml, requirements.txt, setup.py ja yleiset hakemistorakenteet.
Agentin kattavuutta on mahdollista parantaa suhteellisen pienillä muutoksilla. Konfiguroimalla lukusyvyyttä, sallittujen tiedostojen määrää ja analyysin tarkkuutta agentti pystyy muodostamaan laajemman kuvan myös monimutkaisemmista tai epätyypillisemmistä repositorioista. Samalla on hyvä tiedostaa, että esimerkiksi kattavuuden kasvattaminen lisää suoraan kustannuksia.
Mahdollisia jatkokehityskohteita
Jos projektia haluaa viedä pidemmälle, luontevia seuraavia askeleita voisivat olla:
- Laajennettu kieli- ja kehitysympäristötuki
- Projektityypin tunnistuksen laajentaminen
- Älykkäämpi tiedostovalinta
- Yksinkertaisten heuristiikkojen sijaan embedding-pohjainen haku, jolla agentti löytää relevantteja tiedostoja ilman koko repon lukemista
- Muistillinen agentti
- Agentti voisi tallentaa aiempia analyysejä ja vertailla uusia repoja vanhoihin, tai jatkaa analyysiä useassa ajokerrassa
- Moduulikohtaiset alagentit
- Suurissa repositorioissa analyysi voitaisiin jakaa useammalle rajatulle (ala)agentille
- Parempi raportointi
- Yhteenvedon lisäksi agentti voisi tuottaa esimerkiksi “first steps” -ohjeen tai onboarding-dokumentin
Mitä ei kannata kokeilla ainakaan vielä
On tärkeää tunnistaa myös, mitä agentilta ei kannata odottaa:
- Laajennettu kieli- ja kehitysympäristötuki
- Älä yritä pakottaa agenttia lukemaan koko koodipohjaa yhdellä ajokerralla – kustannukset kasvavat nopeasti ja lopputulos heikkenee.
- Älä anna agentille kirjoitusoikeuksia tai mahdollisuutta ajaa koodia ilman vahvaa kontrollia.
- Älä oleta agentin analyysin olevan täydellinen tai virheetön: se on apuväline, ei auktoriteetti.
- Agentti toimii parhaiten silloin, kun sitä käytetään kuten ihmistä uudessa projektissa: apuna kokonaiskuvan muodostamisessa ja seuraavien askelten ehdottamisessa, ei lopullisten päätösten tekijänä.
Vertailua: AI-agentti, AI-avusteinen koodi vai perinteinen skripti?
Sama ongelma – repositorion nopea ymmärtäminen – olisi ollut mahdollista ratkaista usealla eri tavalla. Jokaisella lähestymistavalla on omat vahvuutensa ja rajoitteensa.
Perinteinen skripti
Yksinkertainen skripti olisi voinut listata tiedostot, etsiä tunnettuja tiedostonimiä ja tulostaa raakaa metadataa. Tämä olisi ollut nopea, halpa ja täysin deterministinen ratkaisu. Haittapuolena on, että skripti ei pysty tulkitsemaan sisältöä, tekemään valintoja epävarman tiedon pohjalta tai muodostamaan luontevaa, ihmisen luettavaa yhteenvetoa.
AI-avusteinen koodi
AI-avusteinen lähestymistapa tarkoittaisi sitä, että käyttäjä syöttää esimerkiksi tiedoston sisällön kielimallille ja pyytää analyysiä tai yhteenvetoa. Tämä toimii hyvin yksittäisissä tehtävissä, mutta vaatii jatkuvaa käyttäjän ohjausta. Päätöksenteko säilyy käyttäjällä, eikä kokonaisuus oikein skaalaudu useamman vaiheen prosessiksi.
AI-agentti
AI-agentti yhdistää molempien lähestymistapojen hyvät puolet. Se hyödyntää perinteistä ohjelmakoodia ympäristön hallintaan ja kielimallia tulkintaan ja päätöksentekoon. Agentti etenee itsenäisesti kohti tavoitettaan rajatussa ympäristössä, tekee päätöksiä epävarman tiedon pohjalta ja tuottaa käyttäjälle korkean tason yhteenvedon. Haittapuolena on suurempi monimutkaisuus ja tarve hallita kustannuksia ja rajoitteita huolellisesti.
Tässä käyttötapauksessa agenttipohjainen ratkaisu osoittautui luontevimmaksi kompromissiksi joustavuuden ja hallittavuuden välillä.
Haasteet ja opit toteutuksen aikana
Yksi suurimmista haasteista tässä harjoituksessa oli oikeanlaisen promptin ja agentin päätöksentekologiikan löytäminen rajatuilla kustannuksilla. Käytännön testauksessa kävi nopeasti ilmi, että se, mikä toimi hyvin yhden repositorion kanssa, ei välttämättä toiminut yhtä hyvin toisessa. Repositoriot eroavat toisistaan merkittävästi rakenteen, dokumentaation laadun ja käytettyjen teknologioiden osalta, mikä tekee yleispätevän agentin rakentamisesta yllättävän haastavaa.
Kompleksisuutta lisäävät erityisesti repositoriot, joissa on useampaa ohjelmointikieltä tai useita erillisiä osakokonaisuuksia. Tällaisissa tapauksissa agentin on entistä vaikeampi päätellä, mitkä tiedostot ovat olennaisia ja mihin sen tulisi keskittyä. Tämä korostaa sitä, että agentin suunnittelussa kyse ei ole vain kielimallin valinnasta, vaan ennen kaikkea päätöksenteosta: mitä luetaan, mitä ohitetaan ja milloin on parempi sanoa “ei tiedossa” kuin arvailla.
On myös hyvä huomioida, että blogissa esiintyvät kuvakaappaukset ja osa esimerkeistä saattavat ajan myötä vanhentua. Harjoitus osoittautui sen verran mielenkiintoiseksi, että GitHubissa olevaa koodia tullaan todennäköisesti vielä kehittämään, versioimaan ja laajentamaan uusilla ominaisuuksilla. Tässä harjoituksessa tärkeintä ei kuitenkaan ollut se, mitä agentti lopulta tekee, vaan miten se saatiin tekemään rajattu ja hallittu tehtävä. Toimiva lopputuotos on ennen kaikkea mukava bonus, jota voidaan hyödyntää myös oikeissa tarpeissa.
Lopuksi: miten harjoitus meni kokonaisuutena?
Kokonaisuutena harjoitus onnistui hyvin ja vastasi asetettuja tavoitteita. Tarkoituksena oli rakentaa selkeä, rajattu ja toimiva AI-agentti, jonka avulla AI-agenttien perusperiaatteet tulevat konkreettisiksi. Lopputuloksena syntyi agentti, joka toimii määritellyssä ympäristössä, pysyy kustannusrajojen sisällä ja tuottaa aidosti hyödyllistä tietoa.
AI-agentin toteutukseen kului noin yksi päivä, mukaan lukien testaukset ja tämän blogin kirjoittaminen. Yksi keskeisimmistä opeista oli se, kuinka tärkeää rajaus on. Agentin toimivuus ei syntynyt siitä, että se yrittäisi tehdä kaiken, vaan siitä, että se teki yhden asian kontrolloidusti. Myös kustannusten ja virhetilanteiden hallinta osoittautui olennaiseksi osaksi agentin suunnittelua. Ne eivät ole lisäominaisuuksia, vaan osa itse agenttia.
Harjoitus toimi hyvänä esimerkkinä siitä, miten kielimallia voi käyttää osana ohjelmallista kokonaisuutta ilman, että se ottaa liikaa valtaa tai vastuuta. Lopputulos ei ole tuotantovalmis AI-agentti, mutta se tarjoaa pohjan jatkokehitykselle ja ennen kaikkea käytännön ymmärryksen siitä, mitä AI-agentti oikeasti tarkoittaa.
On myös hyvä todeta, että oma kokonaan erillinen aiheensa on sellaisten AI-agenttien testaus ja validointi, jotka viedään tuotantoon. Kun agentti alkaa tuottaa dataa tai tekemään päätöksiä, tarvitaan mekanismeja, joilla sen tuottaman outputin oikeellisuutta ja luotettavuutta voidaan systemaattisesti arvioida. Tässä harjoituksessa testausta käsiteltiin vain pintapuolisesti.
Terminologia
AI-agentti
Ohjelmallinen kokonaisuus, joka havainnoi ympäristöään, tekee päätöksiä epävarman tiedon pohjalta ja suorittaa toimintoja saavuttaakseen rajatun tavoitteen. Tässä projektissa agentti on yksinkertainen ja tarkoituksella rajattu.
Agent loop (Think → Decide → Act)
Agentin toimintamalli, jossa se ensin kerää tietoa (Think), valitsee seuraavan toiminnon (Decide) ja suorittaa sen (Act). Tätä silmukkaa toistetaan, kunnes tavoite on saavutettu tai rajat täyttyvät.
Onboarding-tason ymmärrys
Yleistason käsitys projektista, joka riittää uuden kehittäjän perehdyttämiseen. Se ei pyri täydelliseen analyysiin, vaan vastaa kysymyksiin: mitä tämä tekee, millä teknologioilla ja mistä koodi kannattaa aloittaa.
Rajattu agentti (Bounded Agent)
Agentti, jonka toimintaa rajoittavat eksplisiittiset säännöt, kuten lukusyvyys, token-budjetti tai kustannuskatto. Rajaukset ovat keskeinen osa agentin luotettavuutta.
“Laiska” agentti (Intentional Minimal Agent)
Kielikuva agentista, joka tekee vain välttämättömän työn eikä yritä analysoida kaikkea. Laiskuus on tässä yhteydessä tietoinen suunnitteluratkaisu.
Kustannustietoinen agentti (Cost-Aware Agent)
Agentti, joka seuraa ja rajoittaa kielimallikutsujen token-määrää ja rahallista kustannusta. Budjettirajat ovat osa agentin päätöksentekoa, eivät erillinen lisäominaisuus.
Hallusinaatio
Tilanne, jossa kielimalli tuottaa uskottavalta kuulostavaa, mutta virheellistä tai keksittyä tietoa. Tässä projektissa hallusinaatioita pyritään ehkäisemään rajaamalla syötedataa ja kieltämällä arvaaminen.
README-first-strategia
Suunnitteluperiaate, jossa repositorion README-tiedostoa käsitellään ensisijaisena totuuden lähteenä projektin tarkoituksesta ja teknologioista.
Fallback-logiikka
Varautuminen tilanteisiin, joissa oletettu tieto puuttuu tai on virheellistä. Esimerkiksi agentti voi siirtyä seuraavaan tiedostoon tai raportoida “ei tiedossa” arvaamisen sijaan.
Deterministinen päätöksenteko
Päätöksenteko, joka perustuu ennalta määriteltyihin sääntöihin, eikä pelkästään kielimallin tuottamaan sisältöön. LLM:ää käytetään tulkintaan ja muotoiluun, ei ohjaamaan koko logiikkaa.
Prompt
Kielimallille annettava ohjeistus, joka määrittää, mitä sen odotetaan tekevän ja mitä sen ei tule tehdä. Hyvin muotoiltu prompt on agentin toiminnan keskeinen ohjain.
LLM (suuri kielimalli)
Tekstipohjainen tekoäly, joka tuottaa ja ymmärtää luonnollista kieltä tilastollisten mallien avulla.



